2018 年 ACML 會議上,Li, Shen & Zhu (2018) 發表了 MI-LSTM(multi-input LSTM,多輸入長短期記憶模型):把欲預測個股、與它最正相關的一群股票、最負相關的一群股票、加上大盤指數,共四條時間序列同時餵進一個改造過的 LSTM,用額外的輸入閘門與 attention 過濾雜訊。論文在滬深 300 成分股上的預測誤差優於所有 LSTM 變形,每日選 20 檔的模擬組合也贏過大盤。
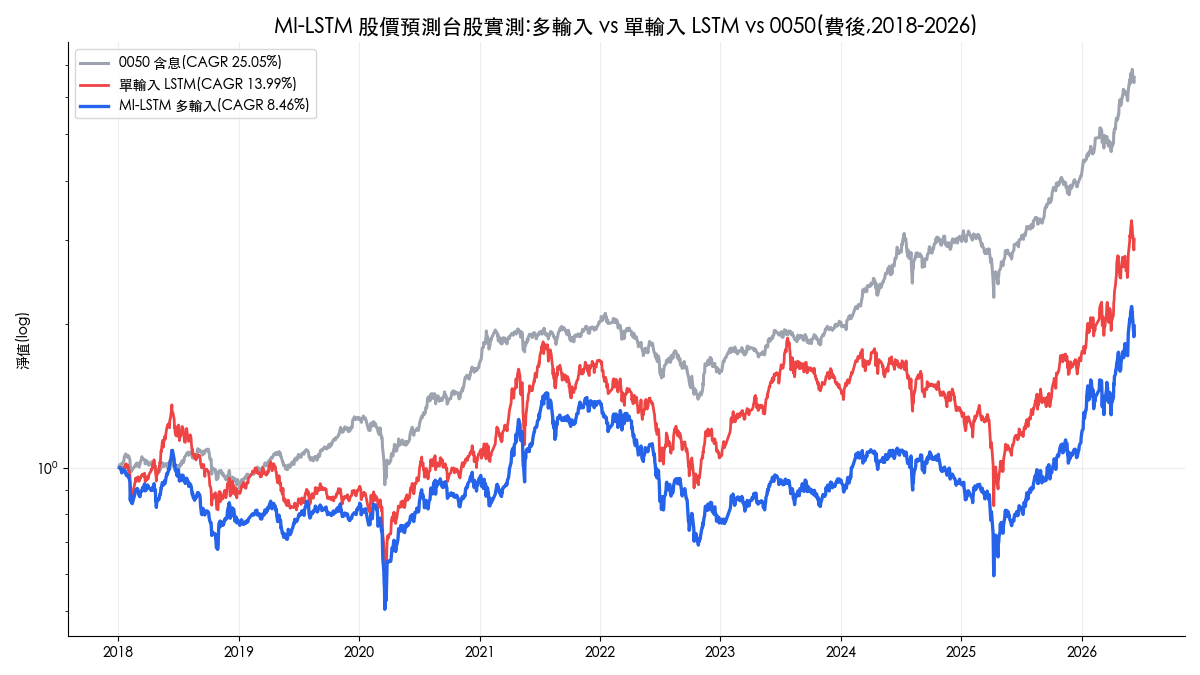
問題是:論文的選股實驗完全沒有計入交易成本,而且只測了中國 A 股 2017 年的 5 個月。這篇文章先把論文的架構與公式講清楚,然後用 finlab 在台股 2018 到 2026 年做了一次完整的樣本外實測:同樣的四條資訊流、同樣每期選 20 檔,改成週頻再平衡並內扣台股實際手續費與證交稅,再拿單輸入 LSTM 與 0050 含息當對照。多輸入有沒有帶來增益?在這個簡化重現裡沒有:MI-LSTM 三種子集成費後年化 8.46%、日夏普 0.43,輸給只用個股自身序列的單輸入 LSTM(13.99%、0.57),離 0050 含息的 25.05% 更遠,預測誤差(MSE)也是單輸入版本較低。論文的閘門設計仍然值得學,但它在台股沒有把預測準度轉成費後報酬;中間每一道報酬的流失,本文都量化了。
結果速覽:台股 2018-2026 費後回測
| 指標 | MI-LSTM 多輸入(週頻 20 檔) | 單輸入 LSTM(對照) | 0050 含息 |
|---|---|---|---|
| 總報酬 | 98.2% | 201.3% | 558.5% |
| 年化報酬(CAGR) | 8.46% | 13.99% | 25.05% |
| 日夏普比率 | 0.43 | 0.57 | 1.22 |
| 月索提諾比率 | 0.78 | 1.13 | 1.92 |
| 最大回撤 | -58.66% | -58.42% | -33.96% |
| 預測誤差 MSE(標準化,9 年平均) | 1.1281 | 1.0597 | — |
回測區間 2018-01 至 2026-06(資料快照 2026-06-09);策略數字內含 finlab sim() 的台股預設交易成本,0050 為含息買進持有、不含成本,口徑差異在文末「回測方法與限制」交代。集成三個隨機種子後,MI-LSTM 在報酬、夏普、回撤每一項都落後對照組與 0050;它輸在哪裡、輸掉的報酬流向何處,後文逐段拆解。
論文想解決的問題:資訊多,雜訊更多
股價預測的研究通常會把各種因子(歷史股價、技術指標、獲利數字、新聞文字)一股腦餵給模型。Li, Shen & Zhu 在論文開頭指出一個尷尬的事實:這些因子大多與未來股價的相關性很弱,訓練時不只浪費計算,有時候反而拖累預測準確度。
他們用一組對照實驗證明這件事:把相關股票的價格序列「直接串接」進標準 LSTM 的輸入(論文稱 LSTM-C),平均 MSE 從純 LSTM 的 1.042 惡化到 1.124(單位 10⁻³,下同)。多給資訊,模型反而變笨,因為雜訊跟著進來了。
MI-LSTM 的解法:資訊照收,但每條輔助資訊流都要先過一道由「主資訊流」(mainstream,欲預測個股自己的序列)控制的閘門,再用 attention 動態分配權重。同一組資料下,MI-LSTM 把平均 MSE 壓到 1.012,優於純 LSTM 與當時的對手模型 DA-RNN(Qin et al. (2017) 提出的雙階段 attention RNN,在這組資料上 MSE 1.706)。
換句話說,這篇論文的貢獻有兩層:一是「相關股票的價格含有可用資訊」,二是「這些資訊必須經過閘門過濾才有用,直接餵反而有害」。
先複習:LSTM 怎麼記住時間序列
LSTM(long short-term memory,長短期記憶模型)是處理時間序列的遞迴神經網路,在每個時間步 用三個閘門(gate)控制記憶的寫入與遺忘:
是遺忘閘(該忘掉多少舊記憶)、 是輸入閘(該寫入多少新資訊)、 是輸出閘; 是 sigmoid 函數,輸出介於 0 與 1 之間,可以理解成「閘門開幾成」。內部記憶(cell state)的更新是:
其中 代表逐元素相乘。直覺上 LSTM 像一條有閘門的輸送帶:舊記憶 沿著輸送帶前進,遺忘閘決定保留多少,輸入閘決定加入多少新資訊。想看更完整的圖解,可以參考 Understanding LSTM Networks 這篇經典教學。
MI-LSTM:四條資訊流與雜訊閘門
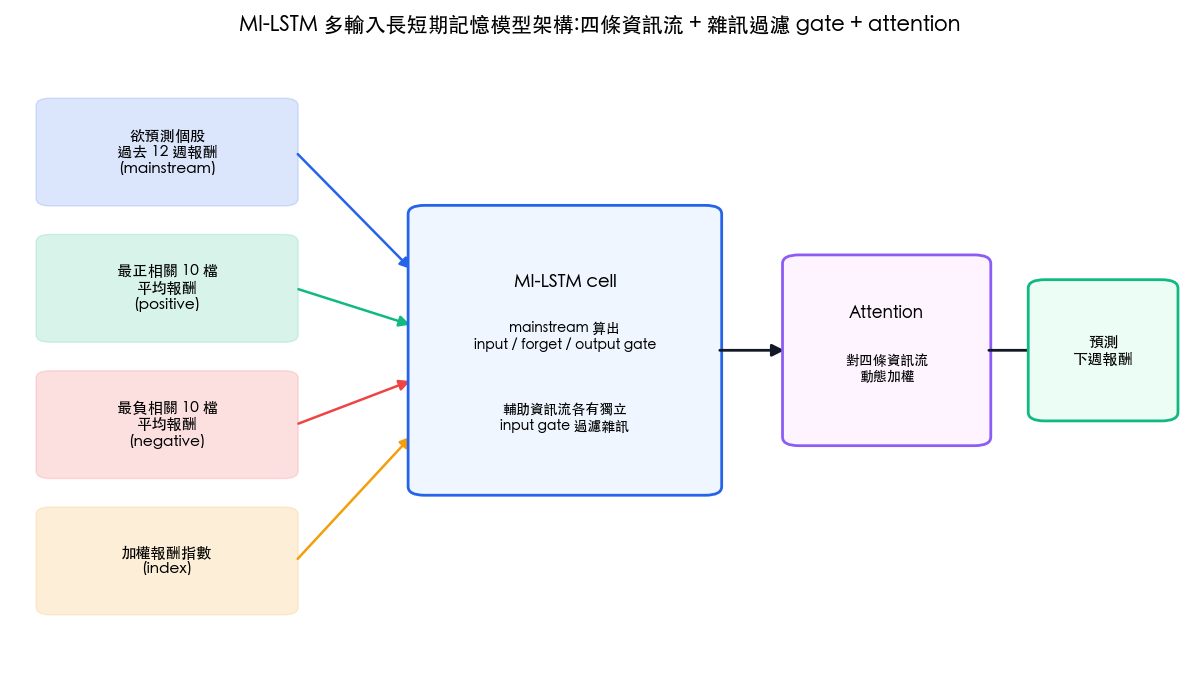
MI-LSTM 的輸入有四類,論文分別記作:
- Mainstream():欲預測個股自己的歷史序列,最可信的資訊。
- Positive():與它最正相關的 檔股票(實務上常是同產業公司),取平均聚合成一條序列。
- Negative():最負相關的 檔股票的聚合序列。
- Index():大盤指數。
四條資訊流各算一條候選記憶(下標 、、 對應 positive、negative、index):
整個架構最關鍵的設計在這裡:四個輸入閘全部由 mainstream 決定,輔助資訊流對「自己能不能進記憶」沒有發言權:
閘門過濾後的四條記憶輸入,再用 attention 加權合併:
attention 權重 由各記憶輸入與前一刻的 cell state 共同打分,經 softmax 正規化:
最後照標準 LSTM 收尾:
論文還有一個聰明的細節:輔助資訊流的權重矩陣 、、 與偏置全部初始化為 0。訓練一開始模型完全忽略輔助資訊,等同純 LSTM;有用的資訊才會在訓練過程中被逐漸引入。這保證了「輔助資訊再爛,也不會比不用更差」。
softmax 加權的小例子
拿一組虛構數字示範 attention 怎麼分配權重(僅為說明計算,非任何實測結果)。假設某一刻四條資訊流的打分是 ,依序為 mainstream、positive、negative、index。softmax 把它們變成總和為 1 的權重:
mainstream 與大盤拿走近七成權重,正、負相關股只分到三成。後面會看到,這個虛構例子的形狀與論文(以及我們在台股)實際訓練出來的權重分布相當接近。
輸入池怎麼選:滾動相關係數
「最正相關」與「最負相關」用 Pearson 相關係數定義。對股票 、 的報酬序列:
手算一個 4 週的迷你例子(虛構數字,僅示範公式):A 股週報酬 ,B 股 。兩者平均都是 ,離差分別為 與 (單位 %)。分子 ;分母 ;相關係數 ,代表兩檔股票幾乎同進同出。
實測中我們對每檔股票用過去 104 週的週報酬,在股票池內算出它與其他股票的相關係數,取最高的 10 檔當 positive、最低的 10 檔當 negative(論文 Table 3 試過 4 到 20 檔,10 檔的預測誤差最低)。下圖是台積電(2330)的實際輸入池:
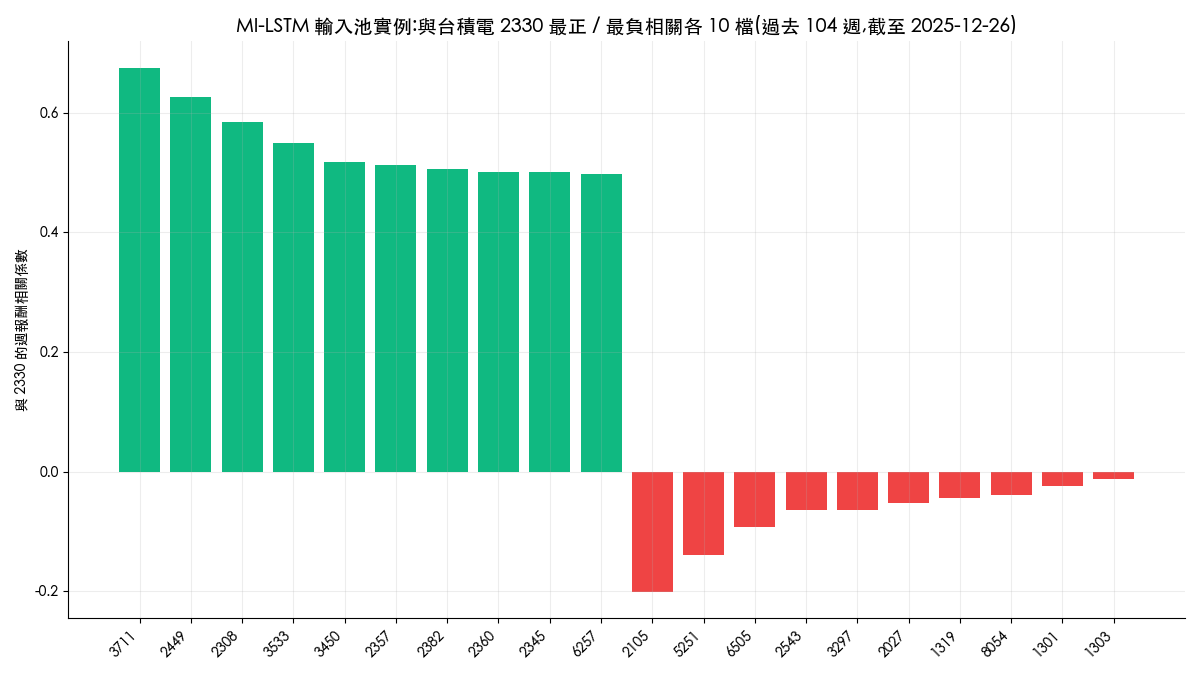
這張圖透露兩件對台股很關鍵的事。第一,最正相關的 10 檔(日月光投控、京元電子、台達電等)清一色是半導體與電子供應鏈,正相關池實質上是產業鏈的代理變數。第二,負相關側非常弱:最強的負相關只有 -0.20(輪胎股正新),其餘多在 -0.1 以內,塑化、營造等傳產只是「不太相關」而稱不上反向。台股長期由電子權值股帶動,幾乎找不到穩定強負相關的股票,MI-LSTM 的 negative 資訊流在台股先天就比論文設定的市場單薄。
原論文的實驗結果(滬深 300)
論文用滬深 300 成分股(剔除歷史不足 4 年的 40 檔,剩 260 檔加指數)2013-04 到 2017-05 的開盤價,切出 171,216 筆訓練、52,200 筆驗證、26,100 筆測試樣本,時間窗 10 天,預測明日的標準化價格。主要結果(平均 MSE,單位 10⁻³,越低越好):
| 模型 | 平均 MSE(×10⁻³) | 說明 |
|---|---|---|
| LSTM | 1.042 | 只用個股自身序列 |
| LSTM-C | 1.124 | 輔助序列直接串接輸入,反而最差 |
| DA-RNN | 1.706 | Qin et al. (2017) 的雙階段 attention RNN |
| MI-LSTM | 1.012 | 輔助序列經閘門 + attention 過濾 |
attention 權重的觀察(論文 Figure 3):訓練收斂後 mainstream 約 0.32、index 約 0.29,positive 與 negative 都掉到 0.2 以下。個股自身與大盤是最有用的資訊,相關股票有價值但雜訊也多,attention 自動把它們降權。
選股實驗(論文 Table 4):每天預測所有股票的隔日報酬,選最高的 20 檔等權持有,不計交易成本。2016-12-14 起算 5 個月,MI-LSTM 的資產從 100 漲到 104.69,同期 CSI-300 指數 99.61、LSTM-C 只有 97.93。
這個結果有三個明顯的限制:只有 5 個月、每日全換股的成本沒有計入、而且只測了單一市場。2020 年我們第一次導讀這篇論文時就指出,日頻換 20 檔在實務上「考慮了手續費後效果可能會打很多折扣,甚至是虧損」,當時建議把預測拉長到週頻來稀釋成本。這次實測就是把這個假說補完:在台股、用週頻、含全部成本,跑完整的 8.5 年。
台股實測設計
實測用 finlab 的還原股價資料,規格如下,與論文的差異也列出來:
| 項目 | 本文實測 | 原論文 |
|---|---|---|
| 市場與期間 | 台股 2018-01 至 2026-06 | 滬深 300,2013-04 至 2017-05 |
| 頻率 | 週頻(W-FRI),預測下週報酬 | 日頻,預測明日標準化價格 |
| 股票池 | 每年依前 52 週平均成交值取前 300 檔 | CSI-300 中歷史足 4 年的 260 檔 |
| 輸入池 | 過去 104 週相關係數,正負各 10 檔 | 同論文最優參數 P=N=10 |
| 訓練 | 每年初重訓(walk-forward),訓練窗 156 週 | 固定切分,訓練一次 |
| 持股 | 每週預測分數前 20 檔等權 | 每日前 20 檔等權 |
| 交易成本 | finlab sim() 內扣手續費 0.1425% 與證交稅 0.3% |
不計成本 |
| 隨機性 | 3 個隨機種子,平均分數集成 | 未揭露 |
關鍵差異是 walk-forward:模型每年 1 月用「過去 156 週」的資料重新訓練一次,當年度的每一筆預測都來自只看過歷史資料的模型,相關係數鄰居集也只用訓練截止前的 104 週計算。整段回測沒有任何一筆預測看過自己的未來,屬於全程樣本外。
核心的資料準備用 finlab 幾行就能完成:
顯示程式碼
import finlab
from finlab import data
finlab.login()
# 還原股價(含除權息)與加權報酬指數
adj = data.get("etl:adj_close")
twii = data.get("benchmark_return:發行量加權股價報酬指數")
# 週頻報酬:每檔股票與大盤
wret = adj.resample("W-FRI").last().pct_change()
idx_ret = twii.iloc[:, 0].resample("W-FRI").last().pct_change()
# 以台積電為例:用過去 104 週報酬,挑最正相關與最負相關各 10 檔
corr = wret.tail(104).corr()["2330"].drop("2330")
positive_pool = corr.nlargest(10).index
negative_pool = corr.nsmallest(10).index
# MI-LSTM 的四條輸入流
mainstream = wret["2330"]
positive = wret[positive_pool].mean(axis=1)
negative = wret[negative_pool].mean(axis=1)
index_stream = idx_ret模型本體用 PyTorch 實作(簡化版的 MI-LSTM cell,約 40 行,完整程式碼可在文末下載)。訓練完成後,把每週的預測分數轉成持股,交給 finlab 回測:
顯示程式碼
from finlab.backtest import sim
# score:模型輸出的週頻預測分數 DataFrame(index=週五,columns=股票)
top20 = score.rank(axis=1, ascending=False) <= 20
# 等權配置後回測,finlab 預設內扣台股手續費與證交稅
position = top20.astype(float)
position = position.div(position.sum(axis=1), axis=0)
report = sim(position, upload=False)
report.display()台股實測結果
整段期間的權益曲線見文首縮圖,三條線的相對位置從 2018 年起就大致定型:0050 含息一路領先,單輸入 LSTM 居中,MI-LSTM 殿後。集成三種子的 MI-LSTM 總報酬 98.2%(年化 8.46%),單輸入 LSTM 201.3%(年化 13.99%),同期 0050 含息 558.5%(年化 25.05%)。風險端更不利:兩個 LSTM 策略的最大回撤都接近 -59%,約是 0050(-33.96%)的 1.7 倍;月索提諾 0.78 對上 0050 的 1.92,風險調整後的差距比絕對報酬更大。下面的互動報告可以檢視 MI-LSTM 週頻策略的逐期持股與回撤:
預測誤差的比較與論文方向相反:9 個年度、3 個種子平均下來,MI-LSTM 的樣本外 MSE 為 1.1281,單輸入 LSTM 為 1.0597,27 組「年度 × 種子」中 MI-LSTM 只勝出 2 組(MSE 為標準化報酬尺度,與論文的標準化價格尺度不可直接比大小)。這未必推翻論文:本文省略了第一層 LSTM 特徵抽取與 temporal attention(細節見「回測方法與限制」),預測目標也從隔日價格改成下週報酬。比較穩妥的結論是:在台股、週頻、輕量實作這組條件下,多輸入架構的增益沒有重現。
attention 權重的分布也值得對照。論文在滬深 300 上看到 mainstream 約 0.32、index 約 0.29;台股的結果:
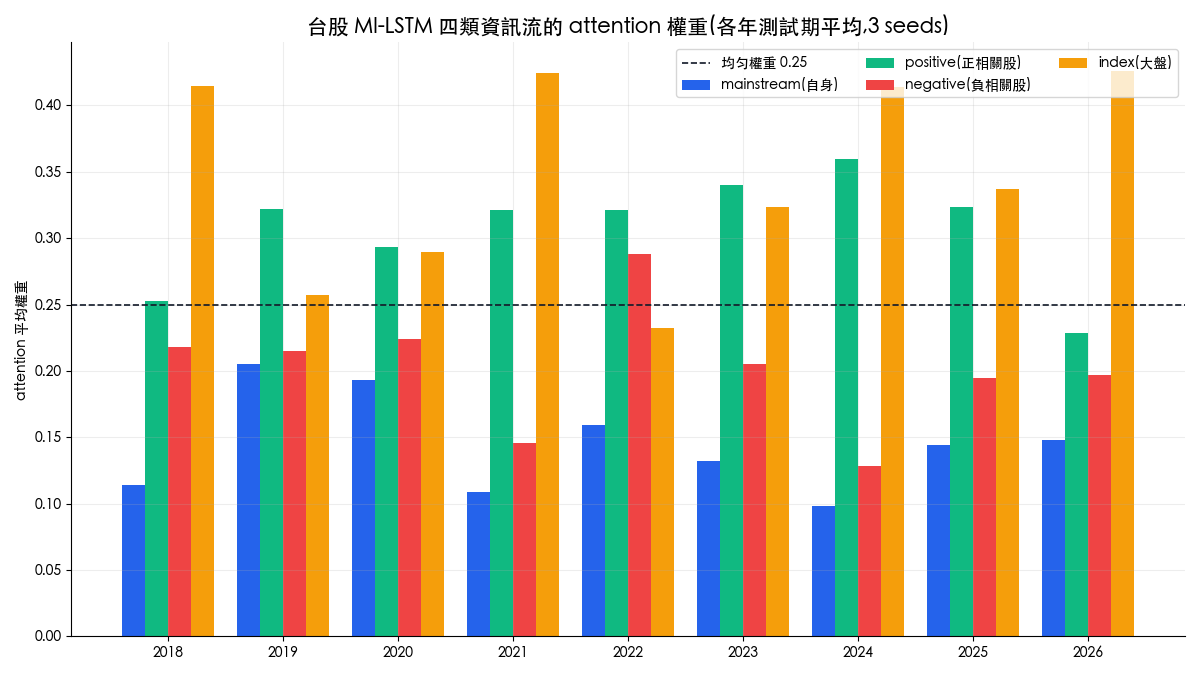
台股的權重分布與論文同中有異。相同的是 index(大盤):9 年平均 0.35,四條資訊流中最高,論文收斂值約 0.29,「大盤對個股影響重大」這個觀察跨市場成立。不同的是 mainstream:論文中它以約 0.32 居首,台股卻只有 0.14 墊底,positive(0.31)反而排第二。一個可能原因是本文把輔助閘門簡化成由各資訊流自己計算,mainstream 失去了論文設計中所有閘門都由它控制的主導地位;另一個解讀是週頻報酬的自我預測力本來就弱,模型把權重讓給了產業鏈與大盤。無論哪個解釋成立,attention 權重對架構細節高度敏感,拿它推論市場結構之前,要先固定架構再比較。
交易成本是這類策略的生死線
原論文最大的缺口是成本。台股買進手續費 0.1425%、賣出手續費 0.1425% 加證交稅 0.3%,一買一賣的摩擦成本約 0.6%。我們的週頻策略每次再平衡的單邊周轉率約 58.5%,代表光是成本,每年就要吃掉可觀的報酬。把再平衡頻率與費率攤開來看:
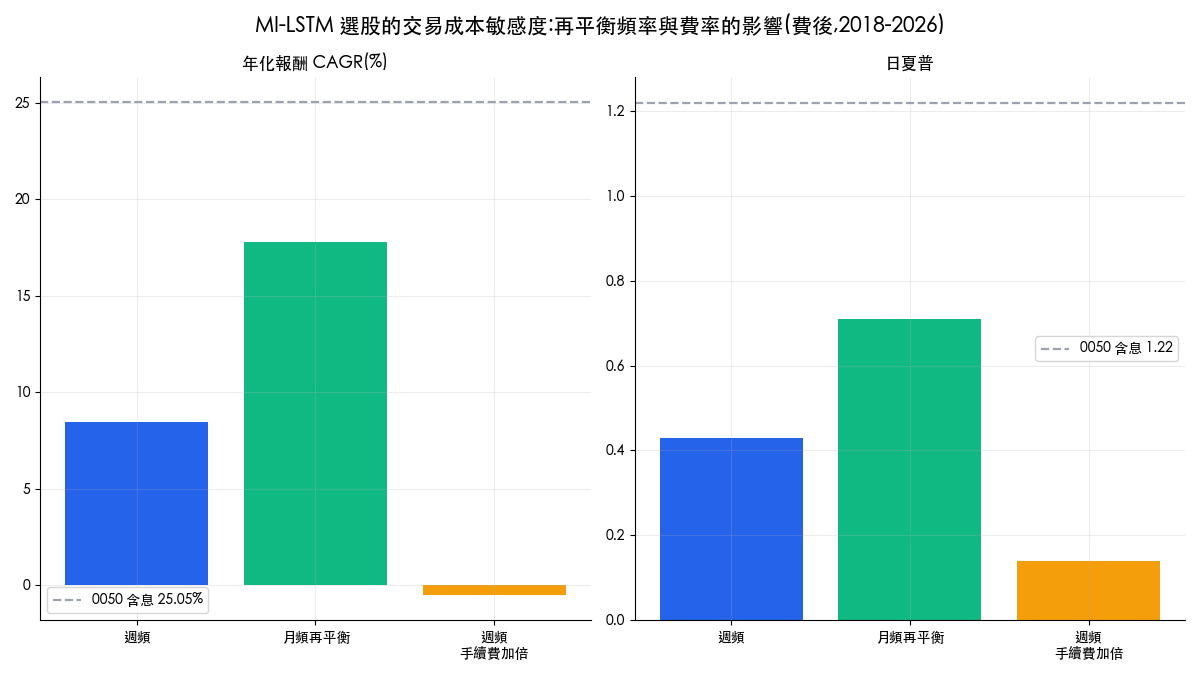
| 情境 | CAGR | 日夏普 | 最大回撤 |
|---|---|---|---|
| 週頻再平衡(基準情境) | 8.46% | 0.43 | -58.66% |
| 月頻再平衡(沿用最新預測) | 17.77% | 0.71 | -45.86% |
| 週頻、手續費加倍 | -0.53% | 0.14 | -70.19% |
| 0050 含息(不含成本) | 25.05% | 1.22 | -33.96% |
三個情境把成本的角色攤開了。同一組預測分數,月頻再平衡的年化 17.77%,比週頻的 8.46% 高出 9.3 個百分點;手續費假設一加倍,週頻策略 8.5 年下來總報酬變成 -4.4%。量化來看:週頻每次再平衡單邊周轉率約 58.5%,台股一買一賣的摩擦成本約 0.585%(雙邊手續費 0.285% 加賣出證交稅 0.3%),每週拖累約 0.34%,一年累積約 16 個百分點;月頻的單次周轉雖較高(85.4%),一年只扣約 6 個百分點。兩者成本拖累相差約 10 個百分點,與實測 9.3 個百分點的年化差距幾乎吻合:週頻與月頻的差距大部分是成本,而非預測力。2020 年導讀這篇論文時,我們猜測拉長到週頻可以稀釋手續費;實測的答案是週頻還不夠長,月頻才讓曲線像樣,而且仍然追不上 0050。若按原論文的日頻全換股操作,成本壓力會再放大數倍:假設日頻的單邊周轉率達 80%(論文每日重選 20 檔,這個量級並不誇張),一年 244 個交易日,光摩擦成本就超過本金的一倍,任何預測能力都填不平這個洞。這也是 Fischer & Krauss (2018) 在 S&P 500 上用 LSTM 大樣本實證的結論之一:LSTM 選股的超額報酬在後期明顯衰減,且對交易成本高度敏感。
穩健性檢查
深度學習策略有一個經典陷阱:換一個隨機種子,結果就變一個樣。我們用 3 個種子各自獨立訓練,主結果採三者平均分數的集成,個別種子的表現如下:
| 隨機種子 | CAGR | 日夏普 | 最大回撤 |
|---|---|---|---|
| seed 0 | 10.18% | 0.48 | -57.28% |
| seed 1 | 8.5% | 0.44 | -61.33% |
| seed 2 | 5.66% | 0.34 | -61.39% |
| 三種子集成(主結果) | 8.46% | 0.43 | -58.66% |
三個種子的年化從 5.66% 到 10.18%:同一套程式、同一份資料,只因初始權重不同,8.5 年的總報酬可以差出一倍以上(59.0% 對 126.3%)。這是深度學習策略與因子策略的本質差異之一,因子規則沒有訓練隨機性,深度學習有;只報告單一種子的回測,等於從抽屜裡挑一張好看的成績單。本文所有主結果都採三種子平均分數的集成,個別種子的離散度也一併公布。
分段來看,策略在不同市況下的表現:
| 期間 | MI-LSTM CAGR / 夏普 | 單輸入 LSTM CAGR / 夏普 | 0050 CAGR / 夏普 |
|---|---|---|---|
| 2018-2020 | -1.81% / 0.06 | 2.43% / 0.23 | 18.33% / 1.05 |
| 2021-2023 | -0.88% / 0.12 | 10.49% / 0.47 | 6.36% / 0.44 |
| 2024-2026 | 35.76% / 1.05 | 34.98% / 1.0 | 62.66% / 2.1 |
分段檢視沒有改變結論:三個子期間 MI-LSTM 全部落後 0050,2018-2020 與 2021-2023 兩段甚至是負的年化報酬,只有 2024-2026 的 AI 行情段跑出 35.76%,但同期 0050 是 62.66%。對照組的型態也一致:單輸入 LSTM 在前兩段都贏過 MI-LSTM,多輸入的相對劣勢遍布全期,並非單一期間的偶然。
回測方法與限制
| 項目 | 本文做法 |
|---|---|
| 交易成本 | finlab sim() 台股預設值內扣:手續費 0.1425%(買賣各收一次)+ 賣出證交稅 0.3% |
| 滑價 | 未假設;訊號為週五收盤,成交以次一交易日收盤價計,實際衝擊取決於資金規模,本文未估算容量 |
| 股票池 | 每年依前 52 週平均週成交值取前 300 檔;只收 4 碼純股票代號,排除 ETF 與權證 |
| 流動性過濾 | 即上述成交值前 300 檔;未另設單日成交量門檻 |
| 排除類別 | ETF 已排除;金融股與 KY 股未排除;要求訓練窗資料覆蓋率 ≥ 90%,隱含排除剛上市與長期停牌股,當年度中途下市的股票仍留在池內由回測引擎處理,生存者偏誤因此有限但非零 |
| 前視偏差 | 特徵只用截至訊號週五的還原收盤價;相關係數鄰居集每年初用先前 104 週固定;模型每年初重訓,只看訓練截止前的資料 |
| 權重 | 預測分數前 20 檔等權,單檔即 5%,無額外上限 |
| 周轉率 | 每次再平衡單邊約 58.5% |
| 樣本內外 | 全程樣本外(walk-forward 每年重訓);無另留驗證集調參,超參數(hidden 32、lookback 12 週等)為一次性設定,未做網格搜尋 |
另外幾點與原論文的實作差異需要說明。本文是輕量重現而非逐行復刻:省略了論文第一層的 LSTM 特徵抽取(正負相關股直接取平均報酬輸入)、省略了 temporal self-attention 層、輔助閘門的條件式與 attention 打分函數也做了簡化、優化器用 Adam 取代 RMSProp。預測目標從「明日標準化價格」改為「下週報酬」,更貼近選股排名的實際用途。這些簡化可能低估也可能高估完整架構的能力,解讀數字時請把它們放在心上。
用 finlab 動手做
想自己跑一遍或改參數(換持股檔數、改相關係數窗口、加長訓練窗),流程是:
- 安裝套件:
pip install finlab,另外需要torch與matplotlib。 - 下載本文完整程式碼:strategy.py,裡面包含資料準備、MI-LSTM cell 的 PyTorch 實作、walk-forward 訓練迴圈與 finlab 回測。
- 執行後會輸出每年的訓練進度、各策略的績效指標與五張圖表;首次執行
finlab.login()時套件會自動引導登入。
如果你還不熟 finlab 的回測流程,可以從程式交易的入門指南開始;想看更多機器學習在台股選股的應用,機器學習選股的完整教學涵蓋了從特徵到標籤的基本功。
常見問題
LSTM 真的能預測股價嗎?
「預測得準」與「賺得到錢」是兩個不同的問題。本文與論文都顯示 MSE 可以做到比基準模型低,但費後報酬是另一回事:本文的 MI-LSTM 在 27 組年度 × 種子的樣本外測試裡,MSE 與費後報酬雙雙輸給更簡單的單輸入 LSTM,兩個模型又都輸給 0050。詳細的討論可以參考機器學習預測股價的正確方法,那篇文章解釋了為什麼直接預測價格往往是錯誤的題目設定。
MI-LSTM 與一般 LSTM 差在哪裡?
差在輔助資訊的處理方式。一般 LSTM 要嘛只看個股自身(資訊不足),要嘛把其他序列直接串接進輸入(雜訊污染,論文實測反而更差)。MI-LSTM 讓每條輔助資訊流經過由 mainstream 控制的獨立閘門,再用 attention 動態加權,做到「資訊照收、雜訊過濾」。
正相關與負相關的股票怎麼挑?
用滾動視窗的 Pearson 相關係數。本文用過去 104 週的週報酬,對每檔股票取相關係數最高與最低的各 10 檔。論文試過 4 到 20 檔,10 檔的預測誤差最低,更多反而變差。
原論文為什麼不算手續費?影響有多大?
學術論文常把交易成本當作工程細節省略,但每日重選 20 檔的策略,周轉率極高。台股一買一賣的摩擦成本約 0.6%,本文實測的週頻策略每次再平衡單邊周轉率約 58.5%,估算下來每年吃掉約 16 個百分點的報酬;費率假設一加倍,8.5 年總報酬從 +98.2% 變成 -4.4%。
訓練 MI-LSTM 需要 GPU 嗎?
本文的規模(每年約 4 萬筆訓練樣本、hidden size 32、12 週時間窗)用一般筆電的 CPU 就能跑,單一年度的訓練在幾分鐘內完成。論文等級的設定(hidden 64、日頻、26 萬筆樣本)有 GPU 會舒服很多,但不是必需。
這個策略適合實際下單嗎?
不建議。理由在內文都有數據:費後年化 8.46%、最大回撤 -58.66%,風險調整後遠不如 0050 買進持有;此外容量與滑價未估算,深度學習模型對隨機種子也有不可忽略的敏感度。把它當成研究多輸入架構的起點,比當成現成的交易策略合適。想找經過更長時間驗證的因子型策略,可以從台股選股的回測總覽入手。
與 CatBoost 這類樹模型相比,LSTM 選股有優勢嗎?
各有擅場。樹模型在截面特徵(基本面、籌碼、技術指標混合)豐富時通常更穩、更省事,可以參考結合技術面與籌碼面的 CatBoost 選股實戰;LSTM 的優勢在時序結構本身,例如本文的多輸入相關性資訊流。實務上不少團隊兩者並用:樹模型做截面排名,RNN 類模型補時序訊號。
如何重現本文的數字?
文末的 strategy.py 是完整可執行腳本,資料截止日釘在 2026-06-09。由於深度學習訓練的隨機性,不同硬體與套件版本可能產生些微差異,但 3 個種子的集成設計會把這個差異壓在小範圍內。
延伸閱讀
- 量化交易完整指南:從回測觀念到策略上線的總覽頁。
- 論文導讀:用 CNN 把時間序列轉成影像來交易 ETF:另一篇深度學習論文的導讀與討論。
- 用深度學習 LSTM 解析 K 線圖:LSTM 的另一種輸入設計,拿 K 線圖樣當特徵。
- 三重屏障標籤法:機器學習選股最容易忽略的標籤工程。
- 用 Qlib 與 finlab 做 AI 選股:微軟開源量化平台的台股應用。
- 量化名詞解釋:夏普比率、最大回撤、樣本外測試等本文用到的指標定義。
回測數據基於歷史資料,未來市場可能出現歷史上沒有的情境。本文所有策略與數字僅供教學與研究用途,不構成投資建議;過去績效不代表未來表現,投資一定有風險,進場前請評估自身風險承受能力。
最後更新:2026-06|回測區間:2018-01 ~ 2026-06(資料快照 2026-06-09)|作者:FinLab 量化研究團隊(經量化研究員審閱)
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始
