把現代投資組合理論(MPT)搬進台股 ETF:每月用過去一年的報酬資料,解出教科書上「理論最佳」的兩組權重(夏普最高的 max-Sharpe 組合、波動最小的 min-variance 組合),再跟最簡單的 1/N 等權同場比八年半。這篇的性質比較像潑冷水的檢驗報告:風險調整後,兩種最佳化都沒有贏過把資金均分成四份。下面有完整的公式推導、效率前緣畫法、權重求解過程,以及「數學上最佳」為什麼在樣本外經常落敗的拆解。
| 配置(2018-01 ~ 2026-06) | 年化報酬 | 日夏普 | 最大回撤 | 年化波動 |
|---|---|---|---|---|
| 0050 含息買進持有(基準) | 25.05% | 1.22 | -33.96% | 20.82% |
| 1/N 等權(月再平衡) | 14.1% | 1.20 | -22.21% | 11.97% |
| max-Sharpe(每月重解) | 15.52% | 1.04 | -25.55% | 15.59% |
| min-variance(每月重解) | 8.78% | 0.92 | -23.52% | 10.01% |
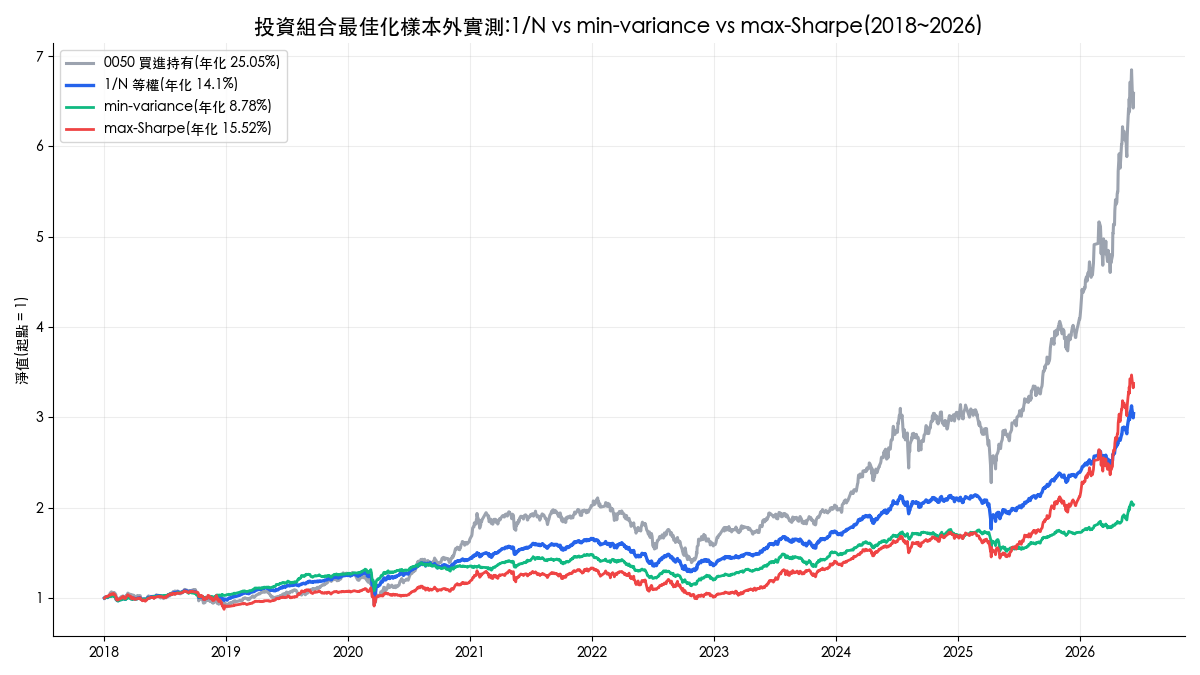
三個值得記住的數字:1/N 的日夏普 1.20,在三組配置中最高;max-Sharpe 的年化報酬 15.52% 比 1/N 高 1.4 個百分點,但波動多了三成、回撤更深;單壓 0050 在這段台股大多頭裡年化報酬最高,代價是 -33.96% 的最大回撤。回測區間 2018-01-01 至 2026-06-09,所有數字由 finlab 套件實跑產出,文末附完整程式碼與淨值資料下載。
為什麼需要投資組合模型
手上同時有台股、美股、債券,各放多少?直覺會說「債券穩,多放一點」,但多放多少才對?反過來問:如果想要一個最大跌幅控制在 -10% 左右的組合,股債比該是幾比幾?網路上常見的 60/40、80/20,又是誰算出來的?
投資組合模型就是回答這些問題的數學工具:把每個資產的報酬與風險量化,求解「給定風險下報酬最高」或「給定報酬下風險最低」的資金分配。Markowitz (1952) 的〈Portfolio Selection〉是這條路的起點:它第一次把報酬(期望值)與風險(變異數)放進同一個最佳化問題,整套框架後來被稱為現代投資組合理論,Markowitz 也因此獲得 1990 年諾貝爾經濟學獎。
有趣的對照是,理論之父自己未必照著理論做。Markowitz 在接受財經作家 Jason Zweig 訪問時說過,他的退休金用的是股債對半的簡單配置,理由是讓未來的後悔最小化。這則軼事背後有嚴肅的學術支撐:DeMiguel, Garlappi & Uppal (2009) 在七組市場資料上測試了 14 種最佳化模型,發現沒有任何一種能在樣本外穩定贏過 1/N 等權,原因是參數估計誤差吃掉了理論上的增益。本文要做的,就是把這場「理論最佳 vs 均分等權」的對決,搬到台灣投資人實際買得到的 ETF 上重打一次。
報酬與風險怎麼量化
報酬模型:權重的加權平均
假設資金分配到一組資產 ,第 檔資產的權重是 、一段期間的報酬率是 ,組合報酬就是加權平均:
粗體的 與 是權重向量與期望報酬向量。限制式 的意思是把一塊大餅切給各資產,本文另外加上 (不放空、不開槓桿)。最佳化的目標之一,就是找一組 讓 變大;但這個「變大」建立在一個關鍵假設上:未來的報酬分布跟估計用的歷史樣本相近。這個假設成不成立,正是後面實測要回答的問題。
風險模型:變異數與相關係數
風險的定義不只一種:有人看最大回撤,有人看下行波動,MPT 選了數學上最好處理的變異數。組合變異數由權重與共變異數矩陣 決定:
兩檔資產的特例把它展開,可以看見相關係數 扮演的角色:
越低,第三項越小甚至為負,組合波動就越低。分散投資的全部數學內涵都濃縮在這一項。
夏普比率:一個分數同時看報酬與風險
報酬要高、風險要低,兩個目標常常打架,需要一個綜合分數。夏普比率把超額報酬除以波動:
是無風險利率(本文取 0 以簡化,詳見回測方法一節)。夏普比率的判讀與計算口徑,可參考夏普比率工具頁;其他名詞的標準定義收錄在詞彙表。
兩資產小算盤:分散為什麼是免費的午餐
用一組示意性數字示範公式怎麼算(僅為計算示例,非任何實際商品的報酬):資產 A 年化報酬 8%、波動 20%;資產 B 年化報酬 3%、波動 5%;兩者相關係數 -0.2。配置 60% 的 A、40% 的 B:
- 組合報酬:
- 組合變異數:
- 組合波動:
如果兩資產完全同漲同跌(),組合波動會是兩者的加權平均 14%。負相關把波動從 14% 壓到 11.8%,報酬一毛沒少,這 2.2 個百分點就是分散的「免費午餐」。它當然也有另一面:分散同時稀釋了單壓最強資產的報酬,這個代價在過度分散如何攤薄超額報酬有完整的實測。
用真資料畫出效率前緣
理論講完,換真資料。股池選四檔台灣投資人都買得到、性質互補的 ETF:
| ETF | 角色 | 年化報酬(2018-01 ~ 2026-06,樣本內) | 年化波動 |
|---|---|---|---|
| 0050 | 台股市值 | 25.47% | 20.82% |
| 0056 | 台股高股息 | 17.88% | 15.54% |
| 00646 | 美股 S&P 500 | 15.4% | 17.37% |
| 00679B | 美債 20 年 | -0.46% | 14.34% |
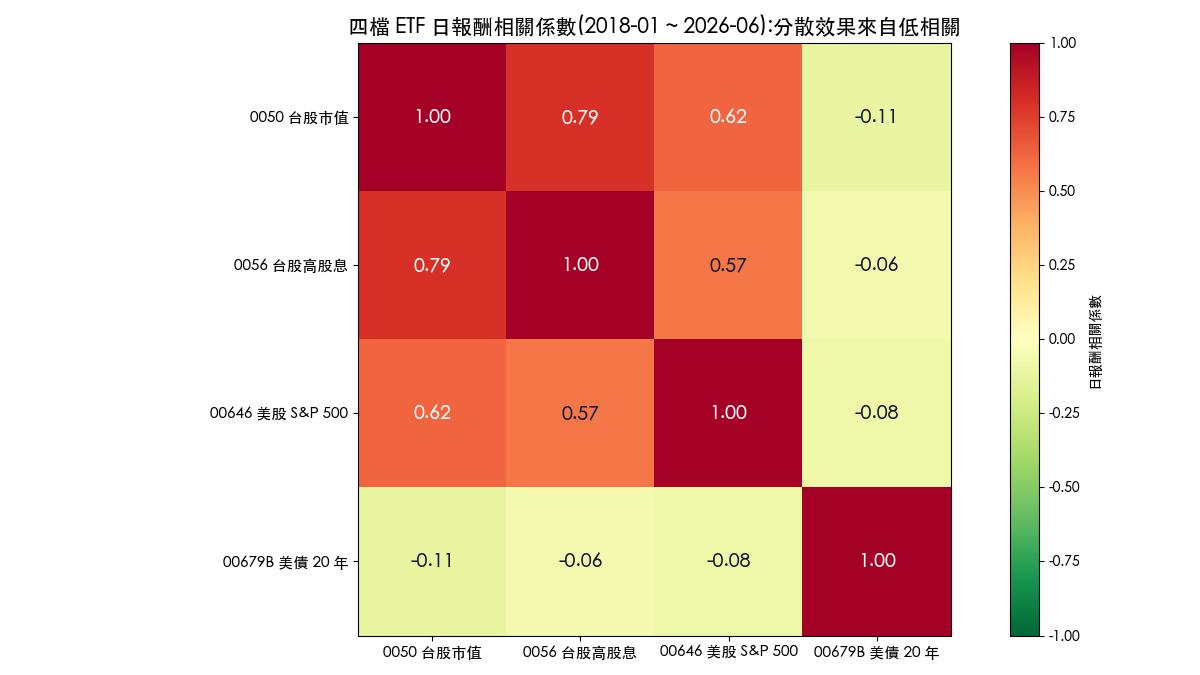
相關係數矩陣透露了分散效果的來源:兩檔台股 ETF 相關高達 0.79,台股與美股之間 0.57 ~ 0.62,真正的低相關全部來自美債那一檔(對三檔股票 ETF 介於 -0.11 到 -0.06)。換句話說,這個股池的分散效果幾乎由 00679B 一檔扛起,而它同時也是樣本內唯一年化報酬為負的資產,這個矛盾會貫穿整篇文章。0056 與其他高股息 ETF 的比較,另見 0056、00878、00919 三大高股息 ETF 量化 PK。
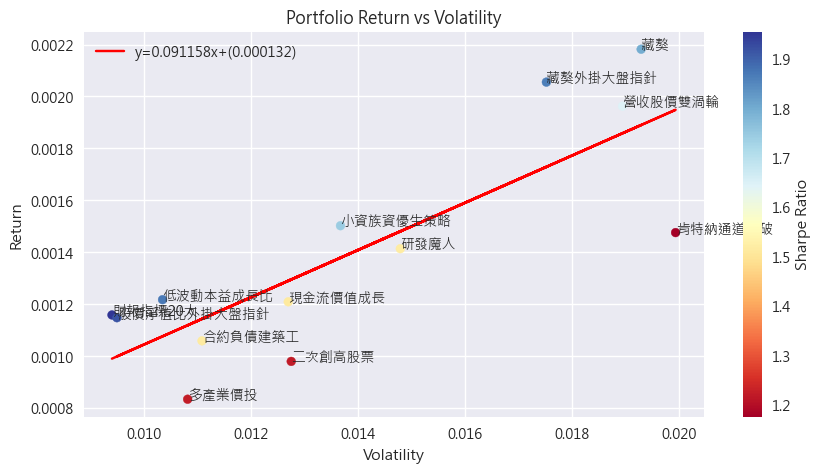
接著用蒙地卡羅法隨機產生 5 萬組權重,每組算出年化報酬與波動,畫在報酬-風險平面上:
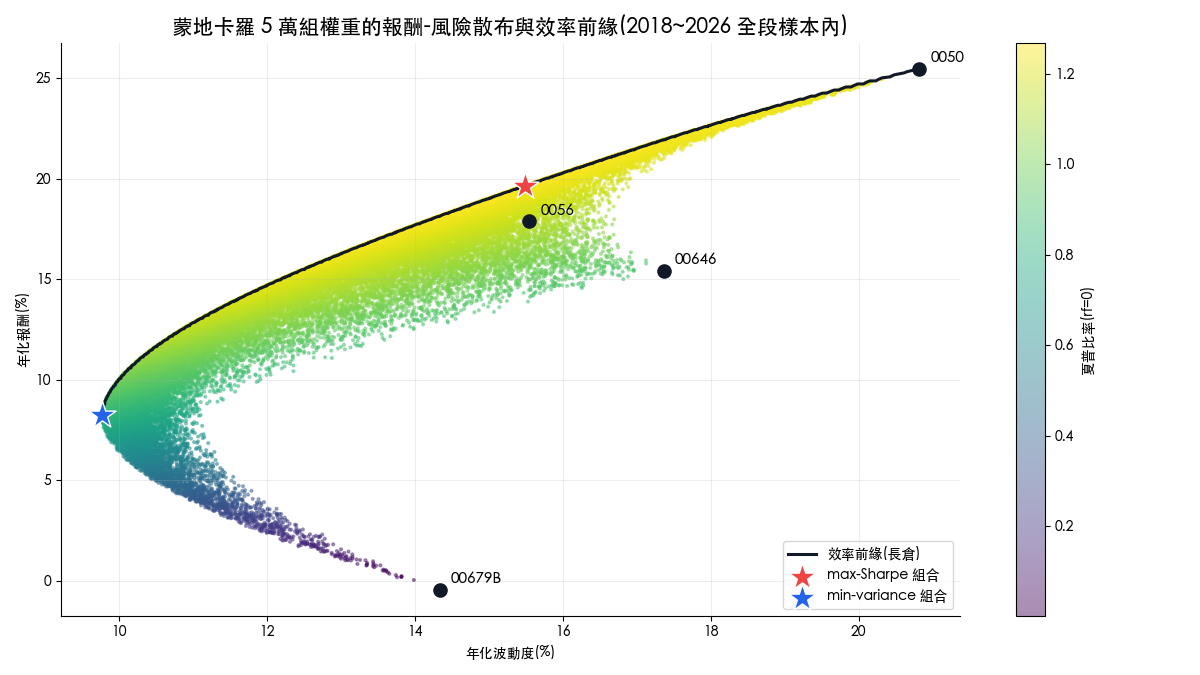
這張圖有幾個讀法。第一,所有可能的配置只會落在一個有邊界的區域內,左上邊界就是效率前緣(efficient frontier):同樣的風險下報酬最高的那條線。第二,顏色代表夏普比率,越往左上越高。第三,圖上兩顆星是兩個有名字的特殊解:紅星是 max-Sharpe 組合(全段樣本內的解為 0050 占 46%、0056 占 36%、00646 占 10%、00679B 占 8%),藍星是 min-variance 組合(0056 占 30%、00646 占 20%、00679B 占 50%、0050 為 0%)。直觀上,現金會落在這張圖的左下角(無風險也無報酬),單一股票會落在右上方,配置的目標是往左上角擠。
要強調的是:這張圖用的是 2018-01 到 2026-06 的全段資料,屬於事後才畫得出來的樣本內結果。星星的位置是「當時不可能知道」的,把它當成可實現的績效是常見的誤讀。
從蒙地卡羅到閉式解
蒙地卡羅是暴力法,數學上其實有解析解。允許放空時,最小變異數組合與切線(max-Sharpe)組合分別是:
兩條公式都要對共變異數矩陣求逆,這個 後面會再出現,它是估計誤差被放大的主要通道。另外,閉式解允許權重為負(放空),與本文「長倉、無槓桿」的設定不符,所以實測時改用 2% 步距的格點掃過全部 23,426 組合法權重,在格點上取波動最小與夏普最高的兩組。格點法的好處是透明:每一組權重都算得出來,沒有黑箱。
樣本外實測:每月重解一次「理論最佳」
效率前緣是用歷史畫的,實戰只能用過去估未來。所以實測採 walk-forward 設計:每個月底,只用截至當天的過去 252 個交易日日報酬估計 與 ,解出兩組最佳權重,下個月生效。對策略而言,每一個月的權重都是事前可得的資訊,績效屬於樣本外。回測的基本觀念與常見陷阱,可參考回測是什麼。
| 項目 | 設定 |
|---|---|
| 股池 | 0050、0056、00646、00679B |
| 估計視窗 | 過去 252 個交易日日報酬(最早一期允許 200 日以上) |
| 重估頻率 | 每月底重估,下月生效(walk-forward) |
| 求解方式 | 長倉、無槓桿,2% 格點掃 23,426 組權重 |
| 對照組 | 1/N 等權(四檔各 25%,每月再平衡) |
| 交易成本 | finlab sim() 台股預設(手續費 1.425‰、賣出證交稅 3‰) |
| 基準 | 0050 含息買進持有(還原價純指數算術,不含成本) |
八年半(2018-01 ~ 2026-06)的完整結果:
| 指標 | 1/N 等權 | max-Sharpe | min-variance | 0050 基準 |
|---|---|---|---|---|
| 總報酬 | 204.1% | 237.6% | 103.4% | 558.5% |
| 年化報酬 | 14.1% | 15.52% | 8.78% | 25.05% |
| 日夏普 | 1.20 | 1.04 | 0.92 | 1.22 |
| 日索提諾 | 1.47 | 1.32 | 1.10 | 1.67 |
| 月索提諾 | 1.63 | 1.88 | 1.32 | 1.92 |
| 最大回撤 | -22.21% | -25.55% | -23.52% | -33.96% |
| 年化波動 | 11.97% | 15.59% | 10.01% | 20.82% |
| 目標權重月均變動 | 0% | 22.1% | 4.2% | 0% |
上方嵌入的是 1/N 等權組合的互動回測報告;max-Sharpe 組合的完整報告可以另開視窗檢視。
幾個重要判讀:
- 日夏普由 1/N 領先:1.20 對上 max-Sharpe 的 1.04 與 min-variance 的 0.92。max-Sharpe 唯一領先的風險調整指標是月索提諾(1.88 對 1.63),其餘指標全數落後等權。
- min-variance 拿到了最低波動(10.01%),卻沒拿到最低回撤:它的最大回撤 -23.52% 比 1/N 的 -22.21% 還深,原因見下一節的權重圖。
- 0050 單壓的年化報酬與日夏普都是全場最高,這是 2018 到 2026 台股大多頭的時代背景;配置組合付出報酬,買到的是把 -33.96% 的回撤壓到 -22% ~ -26% 的防禦力。「該不該為了回撤放棄報酬」沒有標準答案,但至少這筆交換的價格現在有了數字。
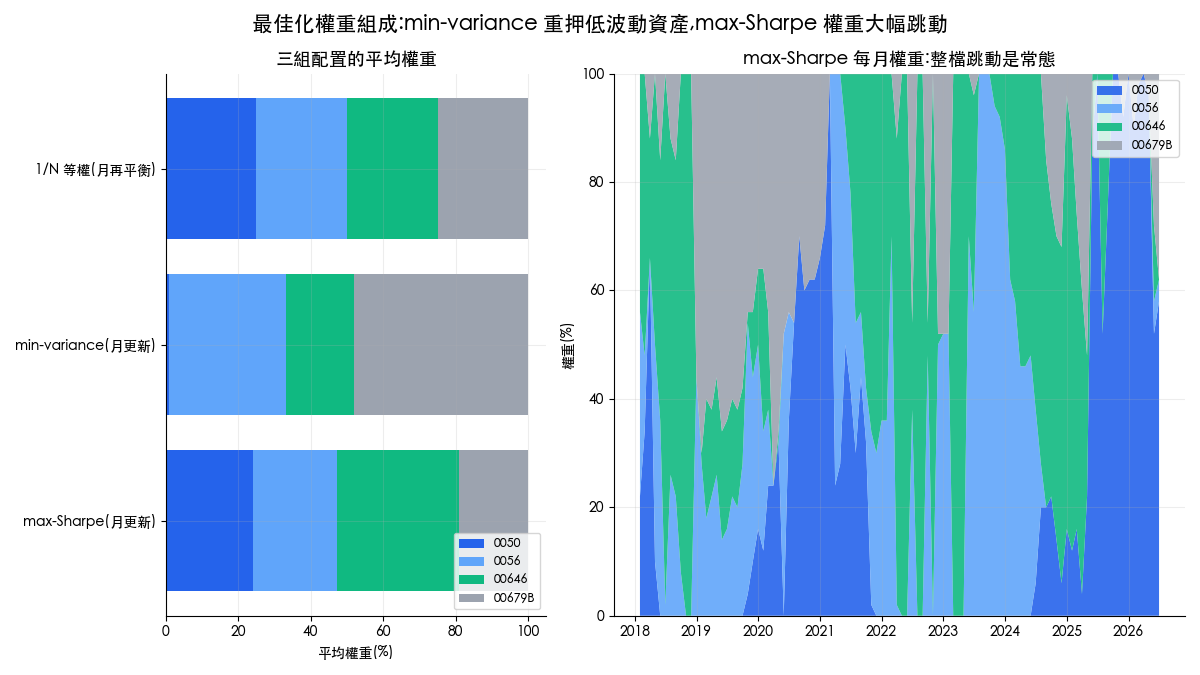
權重圖揭露了兩種最佳化各自的性格。min-variance 平均把 48% 的資金放在美債、32.5% 放 0056,0050 平均只拿到 0.8%:它如實執行了「找波動最低的組合」這個指令,卻因此重押了樣本內報酬為負的資產。max-Sharpe 的平均權重看起來分散(0050 占 24%、0056 占 23.2%、00646 占 33.7%、00679B 占 19%),但右圖顯示每月權重整檔跳動,目標權重月均變動 22.1%,相當於平均每月要把超過五分之一的資金搬家,交易成本與執行難度都跟著上升。
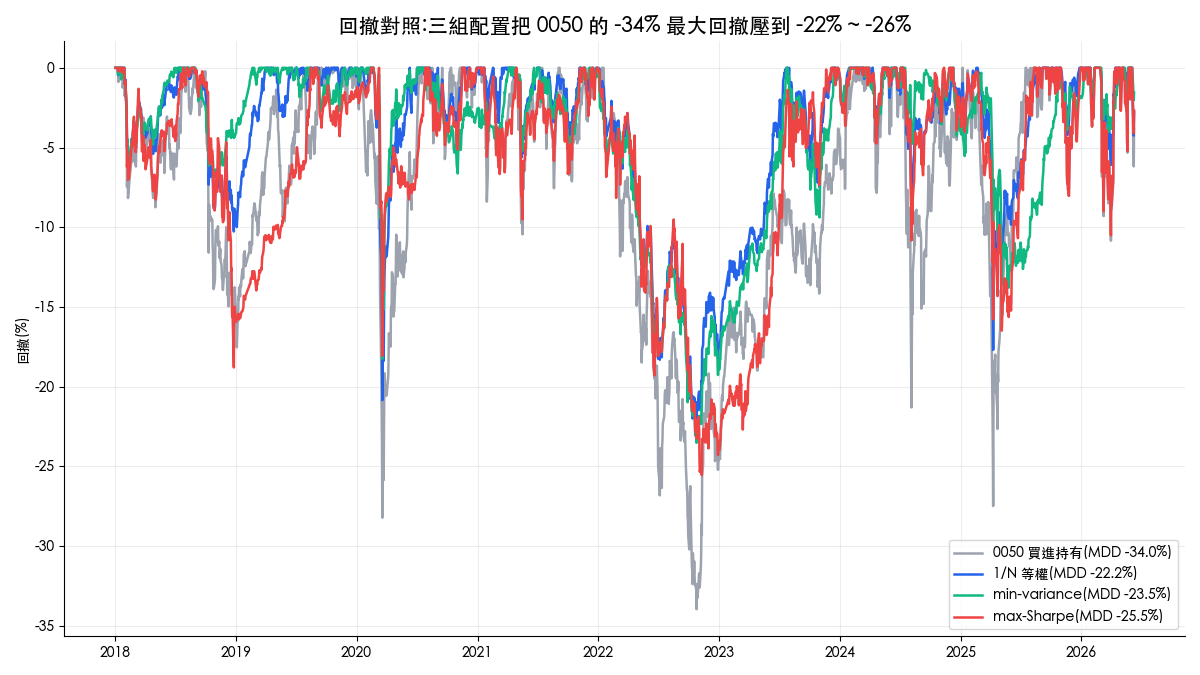
回撤圖則回答了 min-variance 為什麼防禦失靈:2022 年美國暴力升息,股債齊跌,美債 ETF 同步重挫,原本指望的保險在最需要的時候沒有理賠。低波動資產與低回撤資產是兩回事,波動最小化只在「歷史相關性延續」的前提下等於風險最小化,而 2022 正是相關性結構翻臉的一年。
為什麼「數學最佳」輸給「均分四份」
這個結果並非台股特例,學界已經給過系統性的解釋,核心是估計誤差:
期望報酬幾乎估不準。 公式裡的 用過去一年日報酬的平均數估計,雜訊極大。max-Sharpe 對 高度敏感,實際行為退化成「過去一年誰最強就重押誰」,在趨勢延續的行情有利、在風格切換的行情吃虧,後面的分段檢查把這兩種情境都抓了出來。
矩陣求逆放大雜訊。 閉式解與格點解都依賴 的估計,而最佳化過程會優先利用矩陣裡「看起來相關性最美好」的角落,這些角落往往正是雜訊。Ledoit & Wolf (2004) 提出的收縮估計是主流修補:把樣本共變異數矩陣 往一個結構化目標 拉,,犧牲一點偏誤換取大幅降低的變異。本文未實作收縮估計,它屬於「讓最佳化真的有用」的下一步。
需要的資料量大得不切實際。 DeMiguel 等人在同一篇論文估計:以 25 檔資產的組合而言,均值-變異數模型要在樣本外穩定贏過 1/N,需要約 3,000 個月(250 年)的資料來估參數。本文只用四檔資產,估計負擔輕得多,最佳化仍然沒有勝出。
反過來看 1/N 的優勢:它沒有任何參數、沒有估計誤差、目標權重永遠不動,而且每月再平衡自帶「漲多的賣一點、跌深的補一點」的紀律。它輸掉的是理論最適性,贏回來的是穩健性。
穩健性檢查
單一窗口的結論可能只是運氣,所以補兩組檢查。
分段期間:最佳化的好壞看行情臉色
| 日夏普(分段) | 1/N 等權 | max-Sharpe | min-variance | 0050 基準 |
|---|---|---|---|---|
| 2018-01 ~ 2020-12 | 1.23 | 0.55 | 1.19 | 1.05 |
| 2021-01 ~ 2023-12 | 0.63 | 0.44 | 0.43 | 0.44 |
| 2024-01 ~ 2026-06 | 1.74 | 2.05 | 1.19 | 2.10 |
| 年化報酬(分段) | 1/N 等權 | max-Sharpe | min-variance | 0050 基準 |
|---|---|---|---|---|
| 2018-01 ~ 2020-12 | 12.95% | 5.85% | 10.67% | 18.33% |
| 2021-01 ~ 2023-12 | 6.32% | 5.53% | 3.63% | 6.36% |
| 2024-01 ~ 2026-06 | 26.05% | 43.62% | 13.3% | 62.66% |
max-Sharpe 在 2024 年之後的單邊多頭大放異彩(年化 43.62%、夏普 2.05),因為「重押過去一年最強資產」在趨勢行情裡就是動能策略;但 2018 ~ 2020 風格多次切換,它的夏普只有 0.55,全場墊底。1/N 三段夏普 1.23、0.63、1.74,沒有任何一段墊底,它的價值是穩定,而它的對手每一段都在大好與大壞之間擺盪。
估計視窗敏感度:參數一動,結論就晃
把估計視窗從 252 日換成 126 日與 504 日,在三種視窗都可行的共同窗口(2019-07 起)比較:
| 日夏普(2019-07 ~ 2026-06) | 估計視窗 126 日 | 252 日 | 504 日 |
|---|---|---|---|
| max-Sharpe | 0.81 | 1.19 | 0.98 |
| min-variance | 0.69 | 0.83 | 0.77 |
| 1/N 等權(無此參數) | 1.23 | 1.23 | 1.23 |
| 0050 基準(無此參數) | 1.36 | 1.36 | 1.36 |
max-Sharpe 的夏普在 0.81 到 1.19 之間晃動,最好的版本(252 日)仍輸給同窗口的 1/N(1.23)。對「估計視窗長度」這個參數如此敏感,本身就是脆弱性的證據:如果一個方法的成敗取決於你恰好選對回看天數,它在事前是不可依賴的。
回測方法與限制
| 項目 | 本文做法 |
|---|---|
| 交易成本 | 三組配置走 finlab sim() 預設:手續費 1.425‰、賣出證交稅 3‰。ETF 實際證交稅為 1‰,本文未調整,屬保守高估;0050 基準為還原價純指數算術,不含成本 |
| 滑價 | 未假設。四檔均為高流動 ETF,但實際衝擊取決於資金規模,本文未估算容量 |
| 股票池 | 固定四檔 ETF(0050、0056、00646、00679B),非個股選股 |
| 流動性過濾 | 未另設門檻(標的本身為大型 ETF) |
| 排除類別 | 不適用(無個股、無下市風險標的;惟 ETF 池為事後挑選,見下方樣本外說明) |
| 前視偏差 | 權重只用截至每月底的歷史日報酬,下月生效;價格採 etl:adj_close 還原價(含息) |
| 權重上限 | 無單檔上限,格點允許 100% 單押(1/N 固定各 25%)。個股策略的權重上限議題另見持股比例上限 position_limit 實測 |
| 周轉率 | 目標權重月均變動:max-Sharpe 22.1%、min-variance 4.2%、1/N 0%(等權的實際交易來自漂移回補,成本已含在 sim() 內) |
| 樣本內外 | 權重決策為 walk-forward 樣本外;但 ETF 池的挑選(特別是納入美債)帶有事後視角,蒙地卡羅效率前緣圖為全段樣本內示意。無風險利率取 0,高估各組合夏普的幅度一致,不影響排序。發佈後將於季度刷新補上前瞻區間績效,贏輸都寫 |
最早一期權重估計(2017 年底)因 00679B 上市未滿一年,實際可用約 200 ~ 235 個交易日,其後每期皆為完整 252 日。
用 finlab 自己跑一遍
核心程式碼如下,from finlab import data 執行時套件會自動引導登入:
顯示程式碼
import itertools
import numpy as np
import pandas as pd
from finlab import data
from finlab.backtest import sim
# 載入四檔 ETF 的還原價(含息)
etfs = ["0050", "0056", "00646", "00679B"]
adj = data.get("etl:adj_close")
prices = adj[etfs].dropna()
rets = prices.pct_change().dropna()
# 建立 2% 步距的權重格點(四檔權重加總 = 1,共 23,426 組)
n = 50
grid = []
for a, b, c in itertools.product(range(n + 1), repeat=3):
d = n - a - b - c
if d >= 0:
grid.append((a, b, c, d))
w_grid = np.array(grid) / n
# 每月底用過去 252 個交易日,解出 max-Sharpe 權重
weights = {}
for t in rets.resample("ME").last().index:
hist = rets[rets.index <= t].tail(252)
if len(hist) < 200:
continue
mu = hist.mean().values
cov = hist.cov().values
port_ret = w_grid @ mu
port_vol = np.sqrt(np.einsum("ij,jk,ik->i", w_grid, cov, w_grid))
weights[t] = w_grid[(port_ret / port_vol).argmax()]
# 權重表交給 finlab 回測(預設含手續費與證交稅)
position = pd.DataFrame(weights, index=etfs).T
report = sim(position, resample="M", upload=False)
report.display()把 argmax 那行換成 port_vol.argmin() 就是 min-variance,把權重表換成 pd.DataFrame(0.25, ...) 就是 1/N 等權。完整版(含三組對照、0050 基準與指標計算)可直接下載:
| 檔案 | 說明 |
|---|---|
| strategy.py | 完整回測程式碼(含 1/N、min-variance、max-Sharpe 與基準對照) |
| equity.csv | 四條淨值曲線的每日資料 |
常見問題
效率前緣是什麼?
把所有可能的資產權重組合畫在「報酬-風險」平面上,會形成一個有邊界的區域;同樣風險下報酬最高的那條左上邊界就是效率前緣。位在前緣上的組合,找不到「報酬更高且風險更低」的替代品。
投資組合最佳化和資產配置有什麼不同?
資產配置是「決定錢怎麼分」這件事的總稱,方法可以是固定比例(股債 60/40)、等權,或最佳化。投資組合最佳化是其中一種方法:用數學求解某個目標(如夏普最大)下的最適權重。本文的實測顯示,方法更複雜未必結果更好。
股債 60/40、80/20 的比例是怎麼來的?
60/40 源自美國機構投資人的長期慣例:60% 股票提供成長、40% 債券壓波動,恰好落在多數退休金能接受的風險帶。它本質上是效率前緣上「風險中庸」區段的一個粗略近似,並沒有放諸四海皆準的數學必然性;風險承受度不同,最適比例就不同。美股版的股債配置實測見 SPY 加 TLT 低風險投資組合。
1/N 等權這麼簡單,為什麼這麼難贏?
因為它沒有需要估計的參數。最佳化的理論增益要靠準確的期望報酬與共變異數估計來兌現,而這兩者(尤其期望報酬)的樣本誤差極大;當估計誤差吃掉的比理論賺到的多,排名就反轉。DeMiguel 等人的研究與本文的台股 ETF 實測,看到的是同一件事。
min-variance 波動最低,為什麼最大回撤反而比 1/N 深?
它依照歷史共變異數重押了低波動的美債(平均 48%),而 2022 年股債齊跌,歷史負相關失效,美債在最需要防禦時同步下跌。波動最小化保證的是「歷史口徑下」的低波動,並不保證未來的低回撤。
蒙地卡羅模擬要跑幾組權重才夠?
看資產數量。四檔資產時,5 萬組隨機權重已能把可行區域畫得很密;本文求解時改用 2% 格點(23,426 組),因為格點能保證掃過所有角落組合(例如 100% 單押),隨機抽樣反而容易漏掉極端點。資產一多,格點數量爆炸,就得改用閉式解或數值最佳化。
這套方法可以拿來配置自己的多個策略嗎?
可以,把「資產的日報酬」換成「策略的日報酬」,整套流程原封不動。不過策略報酬的歷史通常更短、過擬合風險更高,估計誤差問題只會更嚴重;用分群替代逐一估計的做法,見用 Hierarchical Clustering 配置多策略投資組合。
回測沒贏 1/N,投資組合最佳化就沒用了嗎?
結論是「天真的最佳化很難贏」,而非整個方向無效。收縮估計(Ledoit-Wolf)、對權重加上下限、把期望報酬換成更穩健的先驗(如 Black-Litterman),都是已知能縮小估計誤差的改良。在那之前,1/N 加上紀律性的再平衡,是一個被學術文獻與本文數據同時支持的務實起點。
延伸閱讀
- 量化交易完整指南:從回測到實單的全流程總覽
- 台股怎麼選股?單因子與複合策略實證:配置之前,先把選股這層想清楚
- 程式交易是什麼?:把本文的月頻再平衡自動化的起點
- SPY 加 TLT 公債資產配置回測:美股版的兩資產股債網格
- 用 Hierarchical Clustering 打造多策略投資組合:當配置對象從 ETF 變成策略
- 分散投資的迷思:分散的另一面成本
- 0056 vs 00878 vs 00919 高股息 ETF 量化 PK:本文股池裡高股息那一檔的同類比較
投資有風險,過去績效不代表未來表現。本內容僅供教學參考,不構成投資建議,請依個人風險承受度審慎評估。
最後更新:2026-06|回測區間:2018-01 ~ 2026-06(資料截止 2026-06-09)|作者:FinLab 量化研究團隊(經量化研究員審閱)
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始